Selecting CPU and GPU for a Reinforcement Learning Workstation
Time to read this post: 5 mins
Table of Content
Learnings
- Number of CPU cores matter the most in reinforcement learning. As more cores you have as better.
- Use a GPU with a lot of memory. 11GB is minimum. In RL memory is the first limitation on the GPU, not flops.
- CPU memory size matters. Especially, if you parallelize training to utilize CPU and GPU fully.
- A very powerful GPU is only necessary with larger deep learning models. In RL models are typically small.
Challenge
If you are serious about machine learning and in particular reinforcement learning you will come to the point to decide on the hardware. Maybe you start with some free services like Colab or you use a paid service like Google Cloud Services. I have tried those, but was not happy with the interaction. Also, I did not feel comfortable to never know how much I really will pay. I want to understand things in detail, have fast user interaction and eventually display some real-time graphics. Hence, I decided to build my own deep learning work station. It’s just more relaxing and I think faster in developing deep learning solutions.
But which workstation shall I choose? What CPU? Which GPU will be sufficient?
References
Very helpful resources:
- Which GPU(s) to Get for Deep Learning: My Experience and Advice for Using GPUs in Deep Learning
- Why Don’t You Build a RL Computer?
Workstation
My current setup (good enough for the moment):
- AMD Ryzen 9 3900X (12 Cores, 3.80GHz, 64 MB)
- Asus Prime X570-PRO, AM4 Socket (upgradable to AMD Ryzen 9 3950X)
- RTX 2080 Ti 11GB
- Memory G.Skill Ripjaws V, DDR4, 2 x 16GB (current limitation, but easy to extend)
Total Costs including case, power supply, cooler and SSD: ~2200 CHF (2400 USD)

Nice. Looks small, but is still extendable.
In Detail
I have been running my DDPG reinforcement learning project on CPU for quite some time. To speed up my training time I bought a RTX 2080 Ti. I spent 1000 CHF on the graphics card. But I was very excited to accelerate my training and make the next step forward in the project. However, after GPU installation and adjusting the code to run the training part on GPU - the big disappointment.
GPU utilization was only 2%. Why did I buy a GPU at all?
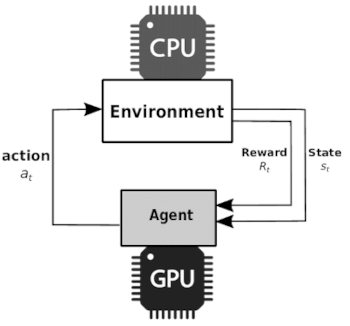
I figured, it is important to understand which code runs on CPU and which on GPU. In reinforcement learning the typical training loop looks like this:
for episode in range(100)
init()
for episode_step in range(1000):
action = agent.predict_action(this_state)
next_state, reward, done = env.step(action)
agent.memorize_transition(this_state, action, reward, next_state, done)
this_state = next_state
agent.train()
A big portion of your code will run on CPU, unless you code up everything in Tensorflow and place the ops on the GPU. Especially the main loop and in particularly the step() function are typically written in Python and will run on CPU. The step() function will retrieve all your states from the environment. It typically accesses libraries such as pandas. The functions with lots of Tensorflow ops are predict_action() and train(), whereas train() will carry the heavy load, doing the back propagation on your model.
The following picture shows the mapping of CPU and GPU to the reinforcement learning functions very nicely
To better understand how Tensorflow assigns the ops use Tensorflow Profiler. This is a screen shot from the Trace View window on Tensorboard.
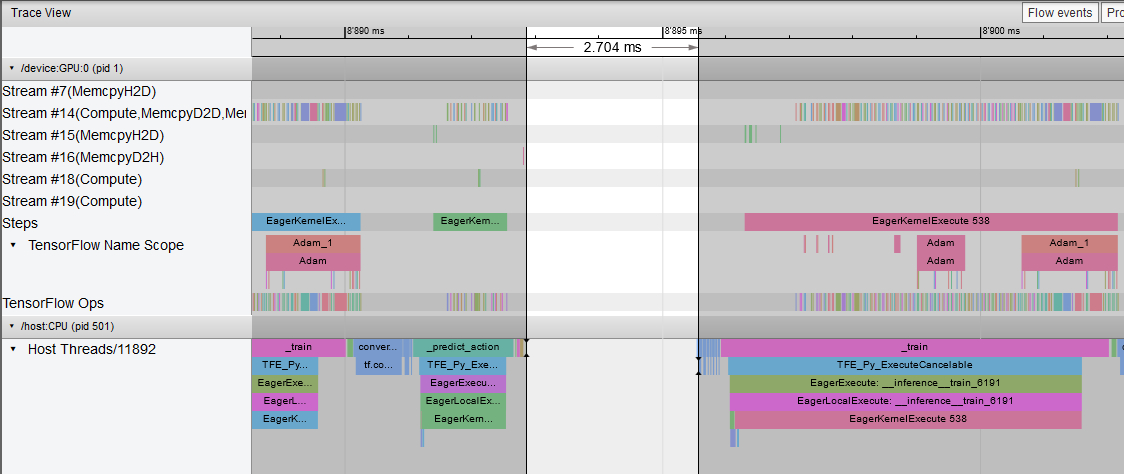
Most Tensorflow ops run on GPU, but there is a big white gap in the chart of 2.7ms. This is the time the CPU spends in step(). As long as predict_action() and step() are run in sequence, the GPU cannot be utilized. That means you have to parallelize your training. You can only parallelize your training if you have multiple CPU cores.
In my case, I simply spun off several python process in parallel to do hyperparameter optimization. Each process uses a different core. This increased the GPU utilization, because multiple processes can access the GPU simultaneously. Of course this also increased CPU and memory utilization. But that was the purpose.
There are other methods to parallelize training (distributed training):
- Distributed Prioritized Experience Replay (APE-X)
- Acme: A new framework for distributed reinforcement learning
- Distributed training with TensorFlow
By parallelizing and separating exploring from learning it is possible to increase utilization of the GPU. However, the decisive factor that determines your GPU load is the model size. As larger your model is, as more computing power is required especially during backpropagation. My model was pretty small. The DDPG actor had only 1218 trainable parameters.
Total params: 1,232
Trainable params: 1,218
Non-trainable params: 14
The critic a bit more:
Total params: 3,441
Trainable params: 3,299
Non-trainable params: 142
This is no comparison to a model used in object detection, where you have tens of thousands maybe even hundred thousands of parameters (i.e. Mask R-CNN or Retinanet). In such a use case (supervised training) a powerful GPU is key. In Rl it is the small size of your model that makes it hard to utilized the GPU fully.
If you parallelize your code it means you are loading a new Tensorflow environment with each process. This is very memory consuming on CPU and GPU (maybe there is a way to keep memory consumption low?). To ensure that not one single process uses up your GPU, make sure to enable this flag in tensorflow:
python os.environ['TF_FORCE_GPU_ALLOW_GROWTH'] = 'true'
In consequence, it means - when you choose a GPU choose a GPU with lots of memory. Aside from the number of CPU cores, this will be most likely your second limiting factor in utilizing your workstation fully. In the end, it is the optimization of hardware and software that will help you to bring out the most power out of your system. Unfortunately, just buying expensive hardware and thinking things will run faster is a wrong assumption.
Result
I decided to choose the hardware in stages, starting with a decent CPU and main board socket that would allow me to upgrade later on. I stuck to AM4 for cost reason. I am still able to upgrade to a AMD Ryzen 9 3950X with 16 cores. Not a huge step, but some flexibility. The current Threadripper line up appeared too expensive too me, especially the new once with the sTRX4 socket. Investing in the older once with the TX4 socket, does not make sense. Hence, I chose AMD Ryzen 9 processor with a good price value. I started training without GPU! Only after I saw that increasing my model size I purchased a RTX 2080 Ti. I am able to integrate two GPU’s running in bridged mode if necessary.
In the mean time my reinforcement learning project is running at approximately 35% CPU and 35% GPU load. Not bad. I was able to balance the load symmetrically. However, my CPU memory is at its limit. I guess it is time to buy some more memory :-).

Command: htop
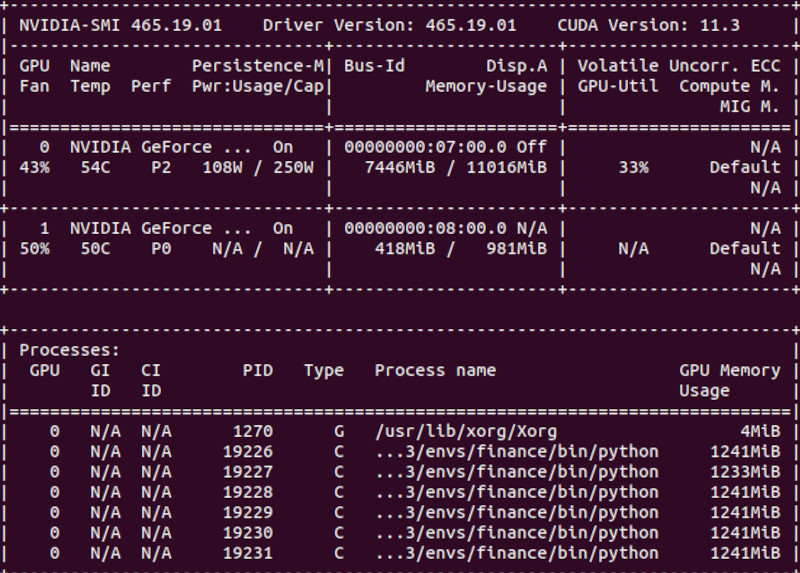
Command: nvidia-smi
Alternatively, you can use Psensor CPU and GPU monitoring tool on linux to monitor your hardware on Linux.
If you have any remarks, questions or suggestions, please do not hesitate and let me know by writing a comment below.
Thank you for reading this post.
Comments
No comments found for this article.
Join the discussion for this article on this ticket. Comments appear on this page instantly.